链表与数组一样同为线性数据结构,不少编程语言也自带了链表的实现,链表可以存放不同数据类型的数据;
与数组不同,数组占用内存结构必须为连续,而链表则不需要内存空间为连续的;链表由多个节点连接而成,每个节点除了存储当前节点的值外还存有指向链表中下一个节点的地址;链表也有多种结构:单链表、双向链表、循环链表等等;
单链表的数据结构如下所示:

通过上图可以看出链表的基本结构,每个节点由值与地址两部分组成,地址存储链中下一个节点的地址,由此将所有 节点串联起来;
链表的优势
相比数组不需要连续的内存空间,系统存在内存碎片也可使用链表;
如需要申请200MB大小的数组,但当前内存中没有足够大连续的内存空间,就算当前可用内存有200MB也不会申请成功;
而链表则不同,只要可用内存有200MB就可使用,不需要内存块为连续的它通过指针将节点(内存块)串联起来;
之前所说的动态数组其实只是伪动态当静态数组满时通过内部的resize创建一个新静态数组进行扩容,而链表为真动态;
1、 数组插入删除
数组为保持内存的连续性插入删除需要移动N个元素,时间复杂度为O(n)
2、 链表插入删除
链表未使用连续内存空间则也不需要移动元素,所以速度会比数组快不少;
由于链表使用的不时连续存储空间,所以不能像数组一样通过寻址公式就能访问到指定的元素,需要通过一个一个遍历每个节点才能找到对应的节点,所以数组的随机访问时间复杂度为O(1),而链表为O(n);
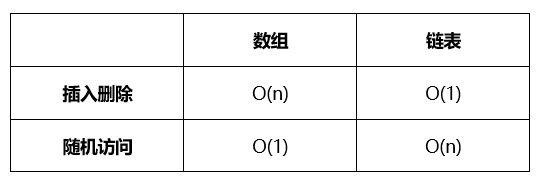
插入删除 O(n) O(1) 随机访问 O(1) O(n)
链表插入与删除
链表的插入与删除比数组快不少,链表并非使用连续的内存空间,不需要去维护内存连续性,就插入与删除而言双向链表又比单链表性能要好;
要在节点c后插入O节点,需要从第一个节点开始遍历链表知道找到节点c然后执行如下操作:
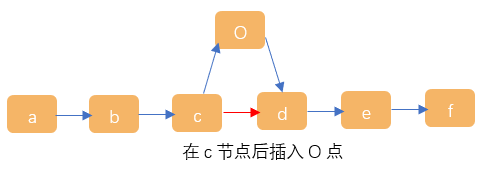
O.next = c.next
c.next = O
删除节点d需要找到该节点的前一个节点,找到节点c后执行如下操作:
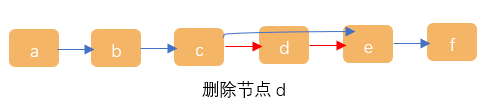
c.next = d.next
d.next = null
由于单链表只存储下一个节点地址需要遍历链表节点才能找到前一个节点,而双向链表既存储了下一个节点地址又存储上一个节点地址,双向链表性能比单链表要好;
链表要点
1、如上面所说的插入元素在c节点后插入O节点,操作时需要注意要先执行O指向c的下一个节点,当一上来就执行c.next=O此时链表c节点后的节点就断开丢失了;
2、链表删除时需要注意要释放节点,如上示例:执行c.next=d.next后如未执行d.next=null此时d节点就未被释放掉,虽然链表中未有节点指向该节点,但该节点并未断开连接;
3、使用头节点简化插入、删除操作;
下面为使用Golang实现的链表
type Node struct {
e interface{}
next *Node
}
type LinkedList struct {
head *Node
size int
}
/**
往链表头添加元素
*/
func (l *LinkedList) AddFirst(e interface{}) {
l.Add(0, e)
}
func (l *LinkedList) Add(index int, e interface{}) error {
if index < 0 || index > l.size {
return errors.New("Add failed. Illegal index.")
}
prev := l.head
for i := 0; i < index; i++ {
prev = prev.next
}
prev.next = &Node{e: e, next: prev.next}
l.size++
return nil
}
/**
nil->3 2 1
查找指定索引节点
*/
func (l *LinkedList) Find(index int) *Node {
cur := l.head.next
for i := 0; i < index; i++ {
cur = cur.next
}
return cur
}
/**
删除指定位置节点
*/
func (l *LinkedList) Remove(index int) error {
node := l.head.next
if node != nil {
if prev := l.Find(index - 1); prev != nil {
node = prev.next
if node != nil {
prev.next = node.next
node.next = nil
}
}
}
return nil
}