DeepSeek-V2.5的时就有听说过,直到 V3出来时开始使用已经体验了一个多月,说实话效果没那么惊艳会莫名从中文会话突然吐出英文。用的官方Web网页稍微多点,Api接口也有在使用其性价比比较高,价格性能相对于其他模型比较便宜,目前注册就送十块钱使用额度。
V3推出时就已经因为其开源、性能、低成本在业内火爆飙到关注度榜首。这几天随着DeepSeek-R1的发布又火了一把,比V3发布时还要更火出圈,主要还是因为它是开源对标OpenAI-o1深度推理模型,而且其基座模型V3训练成本只有557万美元,又是一个名不见经传的小公司搞的,其原本主要也只是稿量化交易的。突然就发布了比肩GPT-4o的DeepSeek-V3其为MoE(混合专家模型)架构模型总参数为671B,激活参数为37B。关键在于其训练成本仅有GPT-4o的十分之一。
这次DeepSeek除了推出推理模型R1-Zero与R1两个660B模型,其基座模型是DeepSeek-V3-Base。R1-Zero只进行了强化学习(RL),R1还使用人类专家标注数据进行监督微调(SFT)。此外还使用DeepSeek-R1模型输出内容蒸馏了6个小模型一并开源,使用了MIT开源协议。
“蒸馏”:从教师模型(DeepSeek-R1)“提炼”知识、训练学生模型(小模型)的方法。最常见做法:把各种输入给教师模型,记录其的输出,然后用这些输入-输出数据训练学生模型。此次开源蒸馏小模型的基座模型为两个系列一个是基于Qwen2.5的另一个是Llama模型的。具体模型为有:
DeepSeek-R1-Distill-Qwen-1.5B
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Llama-70B
其中DeepSeek给出的32B与70B的蒸馏模型跑分性能指标数据对标的是OpenAI-o1-mini模型。在这6个蒸馏模型中1.5B可以用于移动设备或性能不够好的终端等,32B模型将具有很高的可用性。
浅谈
R1是推理模型适合逻辑性比较强的任务,其并不是V3模型的替代模型,R1模型不支持函数调用、不支持JSON输出、不支持FIM补全,两者相互配合使用才能发挥更大的性能。
在实际智能体应用中可以将V3与R1配合混合使用,如在文章编写智能体中可使用V3模型编写文章大纲然后使用R1模型编写每个章节的具体内容;
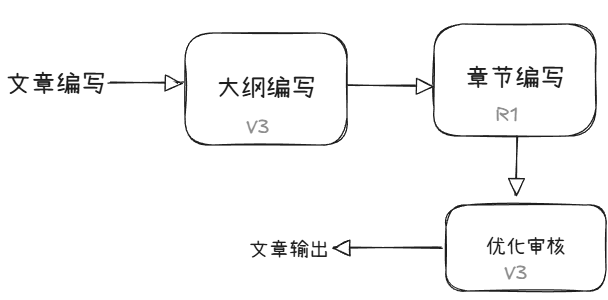
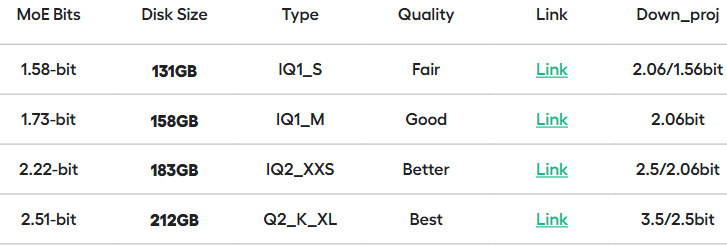
DeepSeek-R1发布后业内关注度飙升并火出圈,R1发布的第二天就有第三方公司发出R1系列各类模型的量化版本,包括R1系列蒸馏模型的的量化版本,量化版本的发布使得R1系列部署门槛进一步降低。下面是unsloth推出的DeepSeek-R1动态量化版本情况。
随着DeepSeek系列蒸馏模型的开源或许将大大降低中小公司部署高质量私有模型的门槛,虽然各种大公司或如DeepSeek这种异军突起的大模型平台公司都提供了API供开发者或各类公司使用也提供了信息安全的资质或保证,但总有不少不信任或不适于使用公网大模型API服务的。高质量的开源私有模型将会加速此类群体对AI的使用。